Cloning microVMs by sharing memory through userfaultfd
How to implement Linux fork in userspace!


At CodeSandbox, we run your development project and turn it into a link you can share with anyone. People visiting this link can not only see your running code, they can click "fork" and get an exact copy of that environment within 2 seconds so they can easily contribute back or play with the code. Give it a try with this Next.js example or import your GitHub repo!
In this post we'll dive into how we enabled this.
A while ago, I wrote a post about how we clone running VMs quickly. It goes in-depth into how we can serialize memory fast (by eagerly writing to disk), and how we can clone it fast (by using Copy-on-Write in the fs) to run a new VM.
However...
There have been two caveats to this approach that we've uncovered over the past months, which made us completely change our approach to cloning VMs. The new implementation has been running in production for six months now, so we figured it's about time to write a new post about how it works.
Let's dive into how we implement fork in userspace!
A quick recap
But first, let's do a quick recap of our initial approach. We were able to clone running VMs within 2s by essentially doing three steps:
- We serialize the memory of the running Firecracker VM to a file.
- We copy that memory file.
- We start a new VM from the new memory file.
This already works with no modifications. The challenge is in speeding this up. We have the goal to create a clone within 2 seconds, and since we're working with big files (4GiB-12GiB), we cannot serialize and copy the file within that time. Ultimately, we were able to work around this by doing two things:
- We eagerly save memory changes to the disk, so that when we need to serialize the memory, most of it has been done already.
- We use Copy-on-Write for copying the file, only copying the memory blocks when they're actually needed by the new VM.
In hindsight, it's interesting to note that we went with two opposite approaches to speed this flow up. We eagerly serialized the memory file, and lazily copied that file as the new VM needed those blocks.
And this works really well... as long as there is not a lot of traffic. As soon as you start running more VMs (50+) on a single node, you will start to see degradation in performance. For us, this meant that we weren't be able to hit the 2 seconds marker anymore. Even worse, sometimes we would see the clone time for a VM jump up to 14 seconds under heavy load.
Why? We've seen two main causes:
The first one is disk strain. The VMs actively write their memory changes back
to the disk. Even though Linux only persists these changes during idle times (as
the mmap is really seen as file cache), it's still many writes. On a fast NVMe
drive you don't see this for a couple of VMs, but as soon as 40-50 VMs are
persisting their memory actively to disk, you start to experience limits.
The second reason is the filesystem, in our case xfs. Whenever we copy a
memory file for a new VM, we do a Copy-on-Write copy by running
cp —reflink=always, which is a
relatively new filesystem feature.
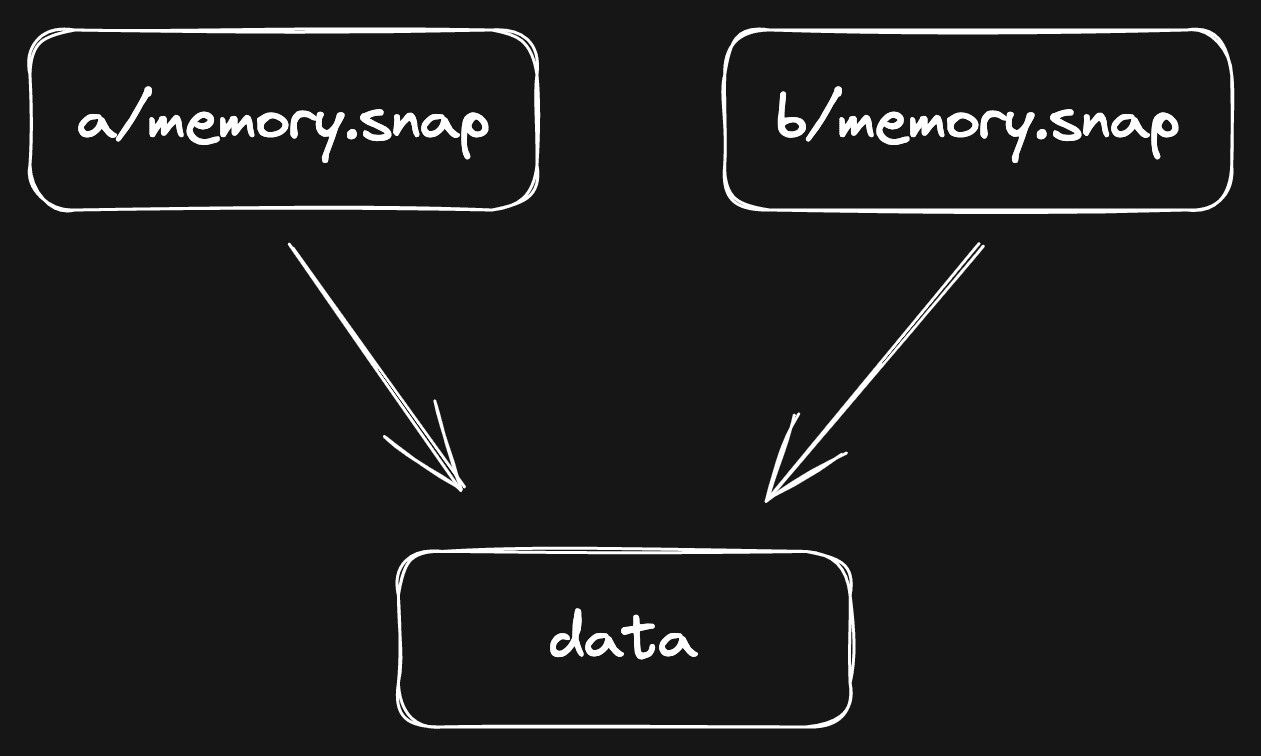
When you do a reflink copy, the filesystem does not really copy the file.
Instead, it creates a file that has a “reference” to the same data. It would
look roughly like this (simplified):
Now, whenever you make a change to the new file, it will:
- Copy the data block to a new one.
- Apply the change on top of the new data block.
Another clear case of Copy-on-Write!
Which would look like this:
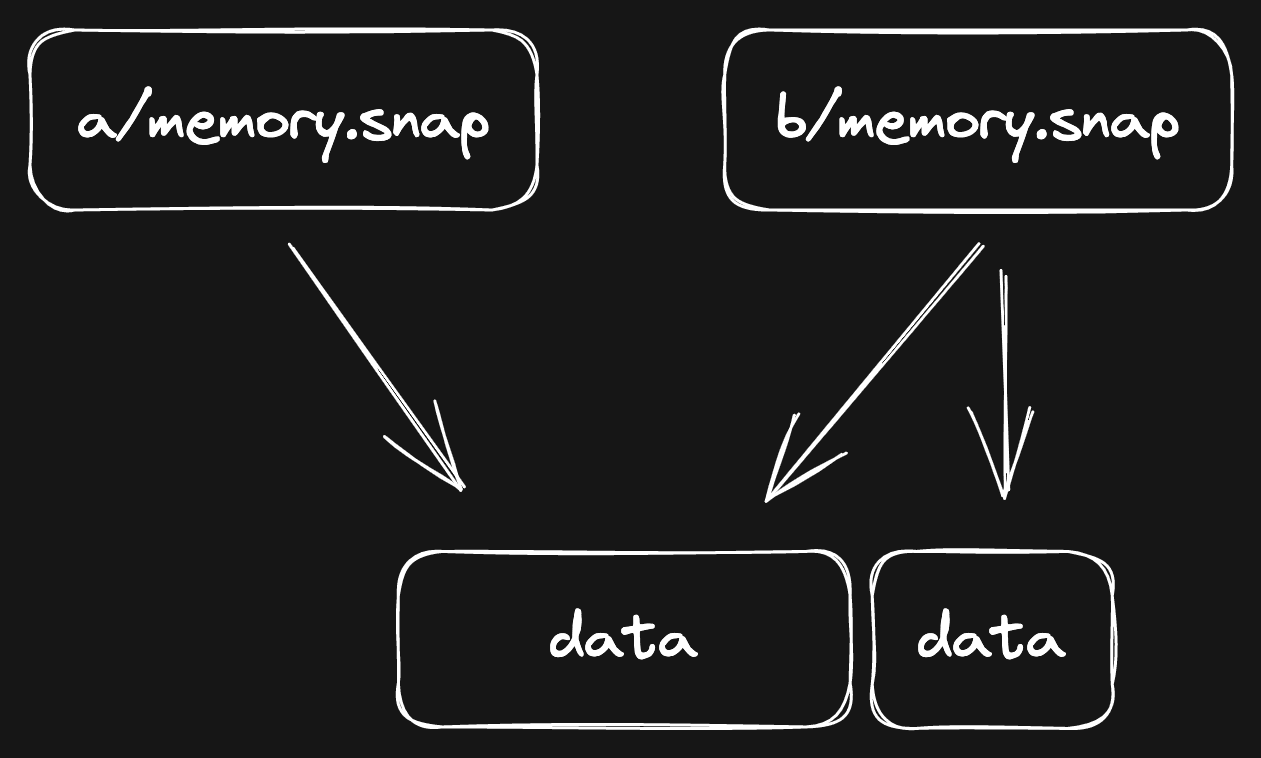
Now, the new file refers to two pieces of data. This has a very small performance
impact: b/memory.snap is now a bit more fragmented. Generally, filesystems are
more efficient when they can load data in contiguous chunks.
As long as you don't do a bazillion edits to the file, you won't notice any performance impact. Unfortunately, we are doing a bazillion edits.
Our VMs sync their memory changes eagerly to the file, which results in over 100,000 little writes at random locations. The memory file gets more and more fragmented, and it will become slower to read the file.
The disk strain and fragmented files led to serious performance problems. So we started asking the natural question: could we skip the disk altogether?
Getting rid of the disk
The immediate first thing we tried out was the simplest approach: copy all memory to the new VM on fork. Whenever you press “Fork”, we pause the original VM and copy all its memory to a new buffer. When we start the new VM, we tell it to use the new buffer.
Unfortunately, this was not fast enough. We can copy the memory with about 2-3GB/s, but that's not fast enough for VMs with 6GB+ memory.
Ultimately, it would be perfect if we can have the same Copy-on-Write (CoW) semantics we had with the filesystem, but in-memory... Something where you can, in essence, spawn new memory that references to its parent...
We were clearly not the only ones who thought about this. In fact, this has
already existed for more than 50 years and pretty much everyone uses it every day. It's the
fork syscall of Unix!
What does fork do?
fork is a very old
syscall. One of the earliest references to fork dates back to 1962. And
still today, it's one of the most used syscalls.
When you call the fork function on Linux, it will create a copy of the
currently running process, and the code will continue running exactly from where
fork was called. It's an exact duplicate—even the variables have the same
value. The only difference is the return value of fork, which is 0 for a
child, and for the parent it's the pid of the child. That's how you know if
you're running code in the parent or the child.
There are a couple more subtle differences between the parent and the child,
which are described in the fork
documentation.
fork is widely used because it's also responsible for starting new processes.
For example, when you run node from your terminal, it won't directly spawn a
new process that runs node. Instead, it will first call fork to clone the
current process, and then call exec in the newly created child to replace the
child process with node. More info about this can be found
here.
In the early days, fork would completely copy the memory of the parent process
to the child process, and then resume the child. However, since fork is such
an important syscall inside Unix, this proved to be too slow for some cases. And
that's why a Copy-on-Write mechanism was introduced.
Instead of eagerly copying all the memory to the child, the memory pages of the parent are marked as read-only. The parent and child both read directly from these memory pages—but when they need to write to a page, the kernel traps that write, allocates a new page, and will update the reference to this new page before allowing the write.
A page is a single block of virtual memory. In most Linux systems, a page is 4096 bytes big. When you read memory, you're actually reading pages.
Because no unnecessary memory is copied, fork is incredibly efficient.
This is exactly what we needed for our VMs! A CoW copy of the memory that the new VM can read from.
So why don't we call fork? Well, because then we would copy the whole jungle,
including disks, network devices, open file descriptors. No, we only want to copy the
memory. That is why we needed to implement a custom version of fork ourselves.
As you'll see, we will replicate the behaviour of fork, but our "fork"
will not work the same way. In our version, we share memory by lazily copying
memory over as the VM needs it, while the syscall fork will allow multiple
processes to reference the same memory as long as it hasn't changed.
Linux UFFD to the rescue
Replicating the behavior of fork... is no simple task, mostly because Linux doesn't make
it easy to control how memory is loaded by a process (in our case, the VM).
In
fact, until recently there was no official (userspace) API in Linux to control
how memory is loaded by a process. That finally changed in 2017, when Linux introduced a new API
called userfaultfd.
userfaultfd is an elegant way to control how memory is loaded, and the missing piece of the puzzle.
userfaultfd (or UFFD for short), allows us to resolve page
faults. So first let's dive into what a page fault is.
When you work with memory, you work with addresses that refer to memory. As a
process, you can reserve some memory (for example, by using mmap) and you get
an address back that refers to the start of the memory range that is assigned to
your process.
Here's an example where we use mmap to get an address from Linux:
But! Linux is playing tricks. The address you get back does not actually refer to memory. Instead, it refers to something called "virtual memory". It acts and looks like real memory, but in reality there's nothing underneath it. Yet.
When you access a virtual memory address for the first time, Linux will catch that call. This is called a page fault (there it is!). The kernel will trap (pause) the request, prepare the physical memory, and then create the mapping between virtual and physical memory. After all of this has been done, it will allow the request to continue.
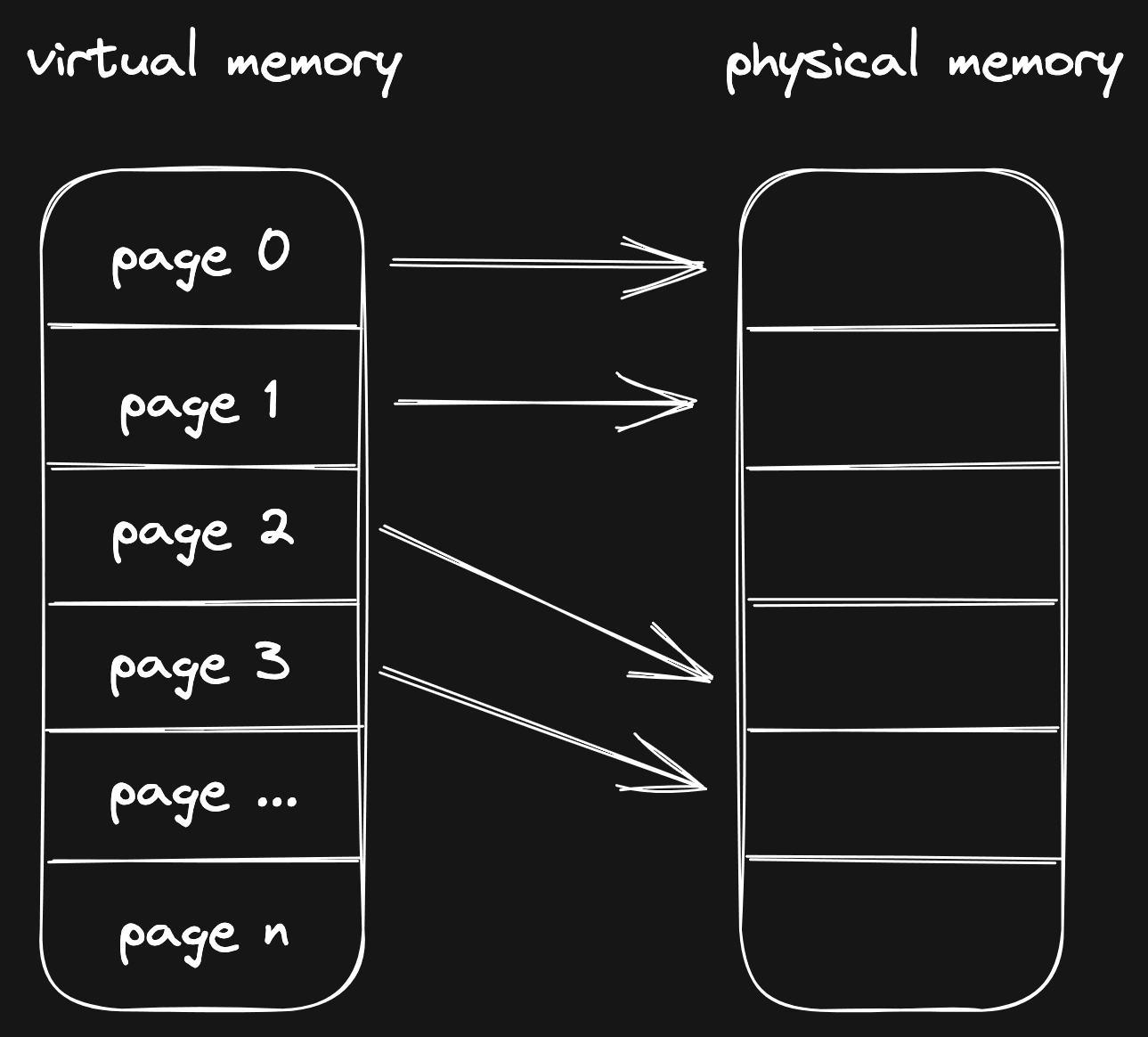
Usually, the kernel is responsible for handling a page fault, but with
userfaultfd, we are allowed to handle page faults!
With userfaultfd, we can tell the kernel that we want to resolve page faults
for a certain memory range—and whenever a page fault occurs in that range, the
kernel asks us to resolve it. When this happens, we can prepare some memory and
put it in the location that was requested. After that, we tell Linux that the
process can continue reading.
The last noteworthy feature of userfaultfd is the ability to catch writes. We can
register a memory range for “write-protection”, and whenever the VM wants to
write to that range, we can trap that write, and do something with the memory.
When we're done, we give a kick to the process to resume.
Write protection support for shared memory is very new. It was introduced in Linux 5.19, which was released on July 31st, 2022. For reference, I started looking into this in October 2022. As you can imagine I was stoked to read that this feature, which is exactly what we need to make this work, was released!
userfaultfd is very powerful, as it gives us full control over how a VM can read
memory. We could theoretically load memory directly from a compressed file or
from the network, or... from another VM!
We have all the pieces, so let's see how we can make this work!
Let's build fork in userspace
Now let's build it! For the examples, I'll often refer to VM A, VM B and even VM C later on. To make it easier to read, I have color-coded the names.
Let's say we have a VM called VM A and we fork VM A to VM B. When this happens, we want VM B to read its memory directly from VM A.
This is possible with UFFD. Whenever VM B tries to read from some uninitialized memory, we catch that read and copy the memory from VM A to make it available in VM B.
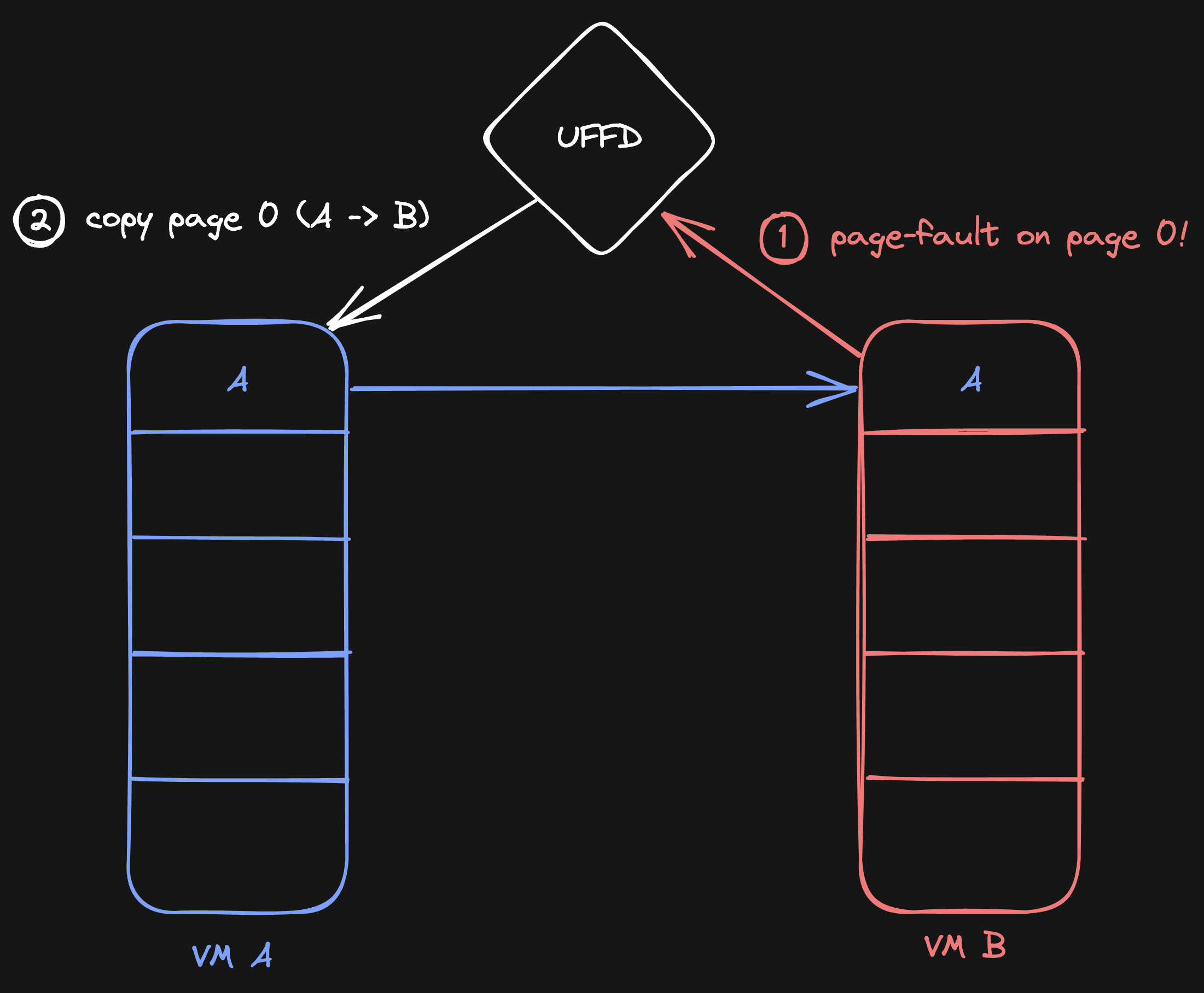
This will lead to a situation where VM B will have the contents of VM A on page 0:
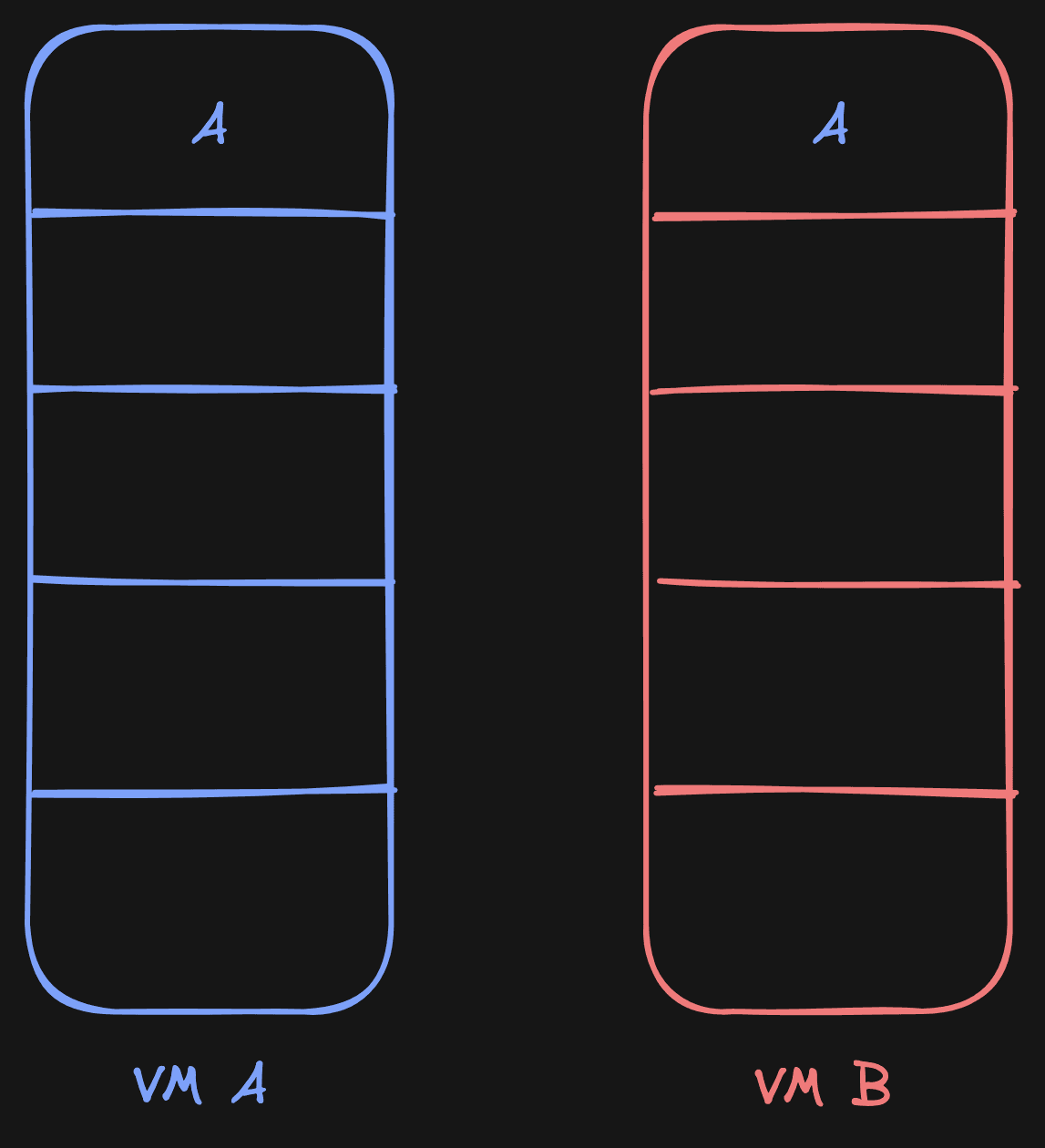
To enable this in practice, we run a program called uffd-handler that
registers itself to manage the memory of VM A and all its children through
UFFD. For every VM, uffd-handler initializes the memory by creating a
memory-backed file (using
memfd_create),
and then it sends the file descriptor of that file to Firecracker. Firecracker
calls mmap on this file descriptor and uses the resulting memory to start
the VM.
So far so good. But what if VM A makes changes to its memory after the fork, before that page has been copied to VM B?
VM B should not get those new changes, as the change happened after the fork. In fact, if VM B were to get those changes, we would be in very undefined behavior. Variables could change unexpectedly. In most cases, the kernel would panic with a big error.
To make sure VM B still gets the old page before the write, we eagerly copy.
As soon as the VM fork happens, we write-protect all memory on VM A. This means that any new writes to VM A will be caught, and the process gets paused. During this pause, we can do with it whatever we want. In our case, we copy the pages to VM B before the new write happens.
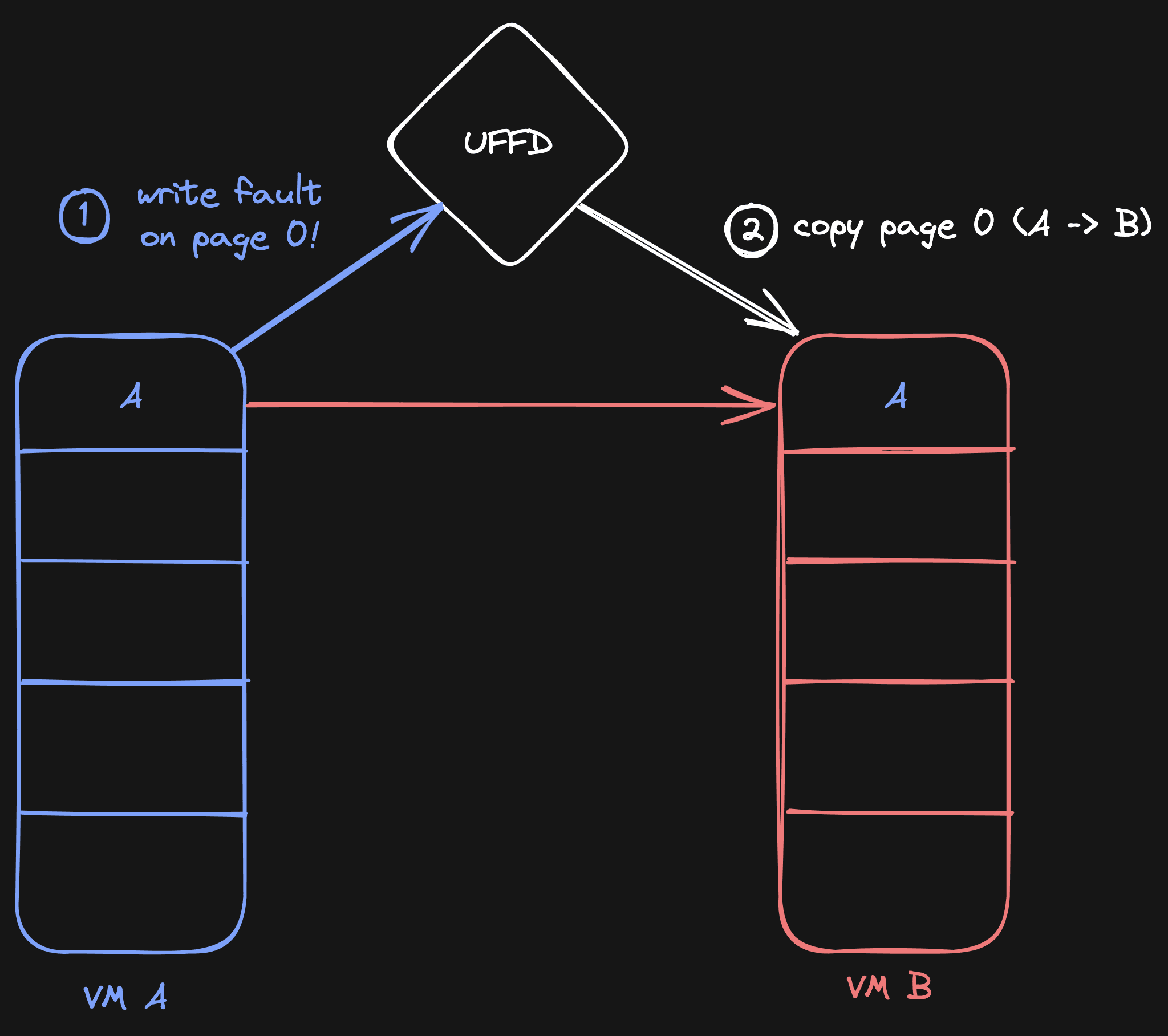
Because we eagerly copy the old memory of VM A to VM B, the memory is not lost. When VM B now tries to read the copied piece of memory, it will not generate a page fault (as the memory was initialized), and so it will also not try to read from VM A.
At the time of implementation, this logic was so new that there still was a bug in the Linux kernel which would sometimes remove write protection when Linux would do internal housekeeping on its memory organization.
This bug was incredibly hard to reproduce. But after 2 months, Peter Xu and I were able to reproduce it. David and Peter fixed it with this commit, which landed in Linux 6.1.8.
Huge thanks to Peter for his patience and persistence in finding this bug. It required an email thread of 85 emails to find and fix this, with an emotional rollercoaster to match, but we found it!
With these changes, we have our first version working! We can now fork a VM, and the child VM will read its memory from the parent VM lazily.
But what about children of children? Well, that is where it becomes more challenging.
Grandchildren & Siblings
Let's get back to the original example. We have VM A, and then we have VM B. Now we fork VM B to VM C. Do all our assumptions still hold up?
Not really. Because of this scenario:
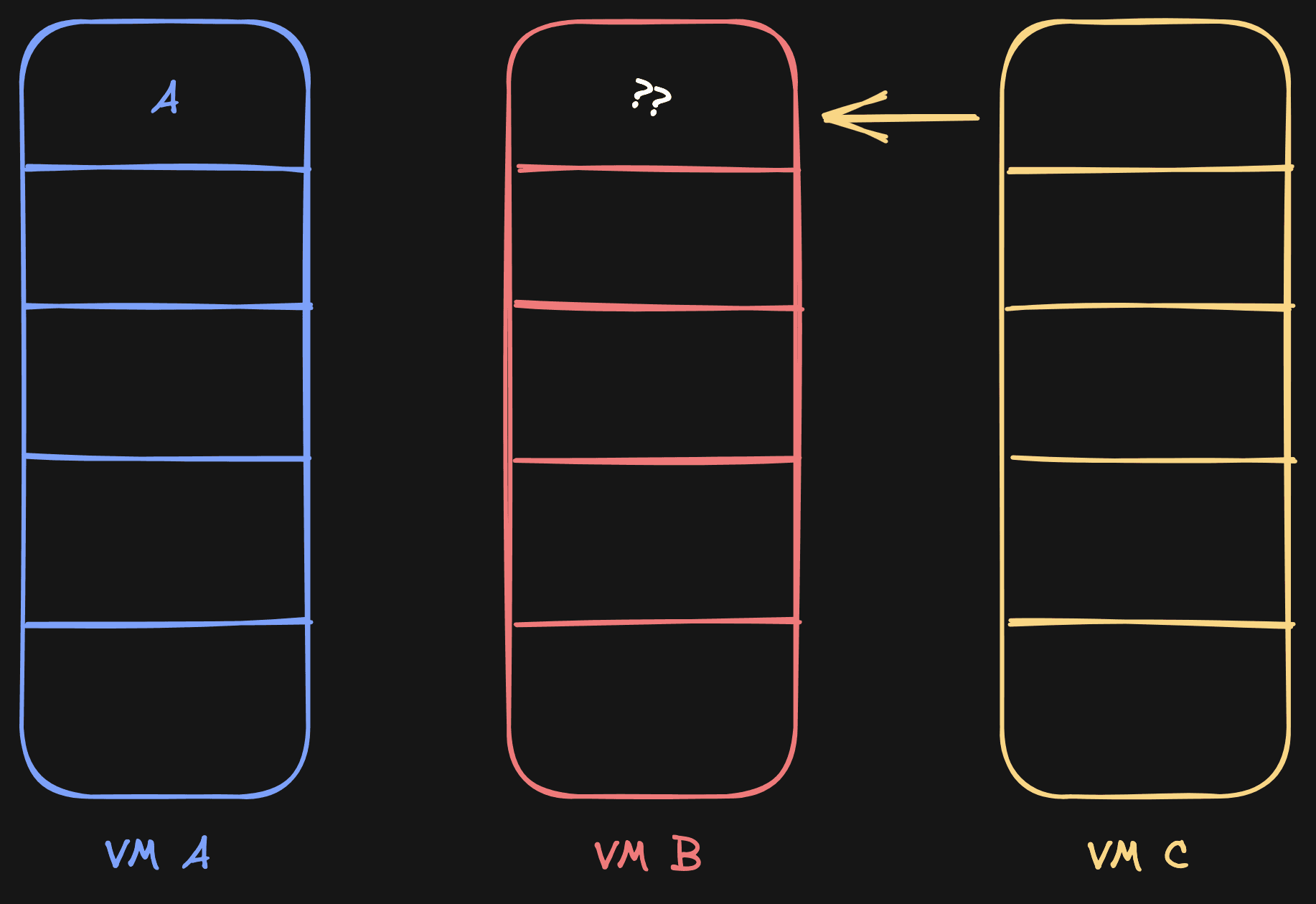
C needs to read page 0, so it checks B, but B doesn't have the page initialized from A yet. This is problematic.
One simple solution would be to copy the page from VM A all the way up. So copy from A to B, and then from B to C. However, the disadvantage of this is that it uses more memory and takes longer.
No, ideally C should read directly from A.
Initially I tried to fix this by letting C traverse all the way up until it finds an initialized page. This sounds sensible, but it has a bug. What if A gets forked to B, then B goes to C, and then VM B gets page 0 initialized? How can VM C then get the page from VM A? If it would traverse up, find a page on VM B, but it needs the page from VM A, because when the fork happened VM B didn't have the page yet.
And yes, it gets even more complicated when we also throw writes into the mix. Back to the drawing board!
Using a Page Sources Table
The problem is that we need to know for any given page where we should read it from. When we have a VM C, we need to know exactly that page 2 comes from VM A, that page 3 comes from VM C, and so forth.
That's when the final piece of the puzzle revealed itself: we shouldn't dynamically determine where we need to read a page from, we should instead keep track of the source of each page. A page source table!
It works like this: whenever we initialize a new VM (let's say A), we initialize a list for that VM. The list defines for every page where we should read it from. This list is big. As mentioned earlier, a memory page is 4096 bytes in most operating systems. So if a VM uses 4GiB of memory, we need 4GiB / 4096 bytes = 1,048,576 elements!
This can potentially take a lot of memory. That's why we're only storing pointers in this list, and these pointers often point to the same object in memory: a PageSource. This is done by using Rc<T> in Rust. Now every element in the list is one pointer (8 bytes), so for a 4GiB VM that's 1,048,576 * 8B = 4MiB to track its sources.
Every element in the list points to a PageSource, which is an enum that describes where we need to fetch the page from. For simplicity, let's say we have 2 sources:
enum PageSource {
Uninitialized, // Memory is not initialized (all zeroes)
Vm(String) // Memory is from a VM with id defined by the String (e.g. VM("A"))
}When VM A starts for the first time, all the items in its list will be
PageSource::Uninitialized, since the VM is starting from scratch:

Now, as soon as VM A starts reading from a page, we handle the page fault as usual and initialize the memory. However, we now also mark that page in our list as PageSource::Vm("A")! This way we know that this page is not empty anymore and has been initialized by VM A, it effectively has itself as source.

This is where the powerful part of this approach comes in.
Let's say VM A gets forked to VM B. To initialize the page source table of VM B, we now only have to copy the source table from VM A! Since we only copy a bunch pointers, this usually happens within ~5-30ms.
Now, when we resolve a page fault for VM B, we know exactly for that page where to
resolve it from. It can be Uninitialized (fill with zeroes) or VM(A), which
means copying from VM A.
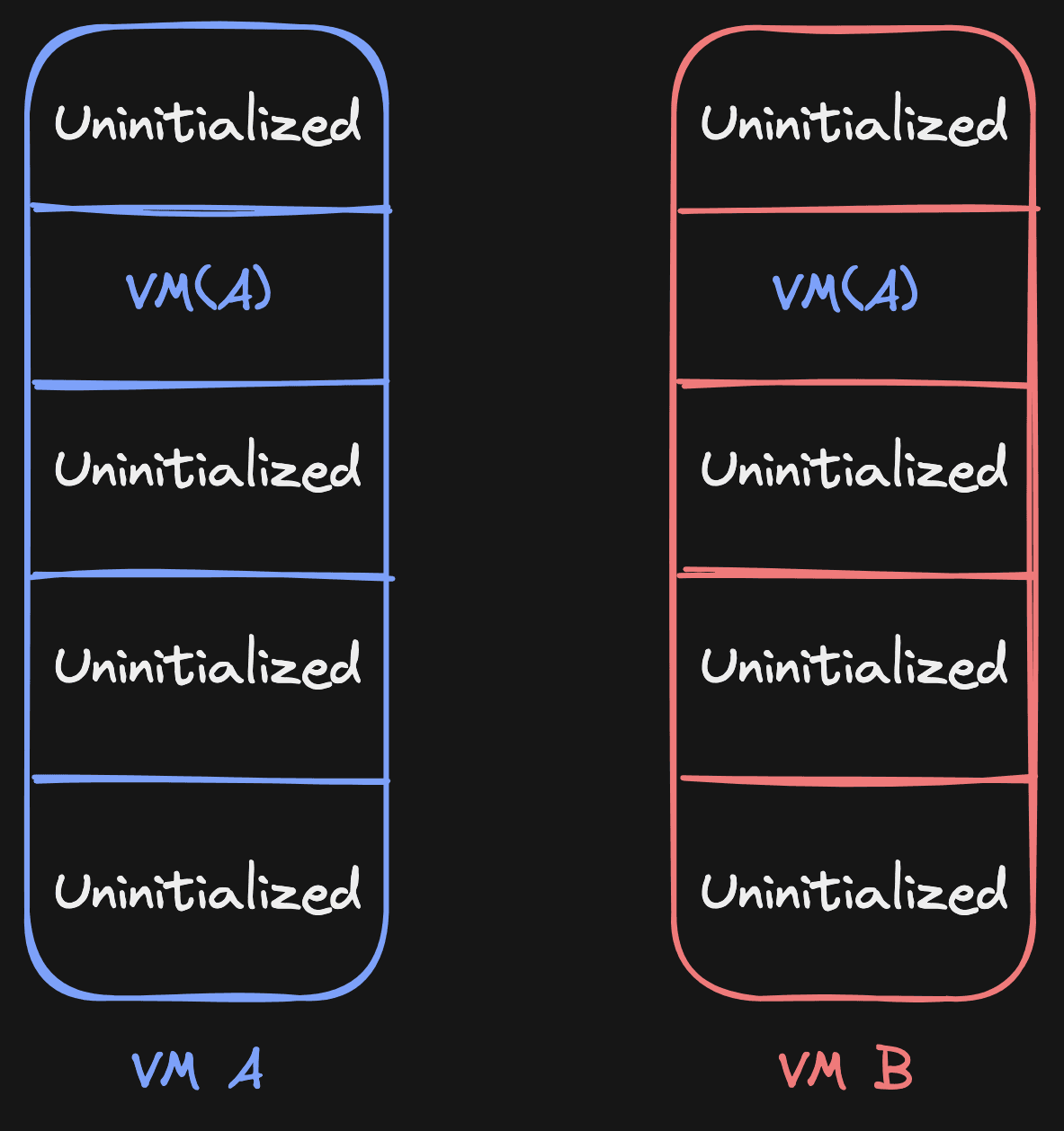
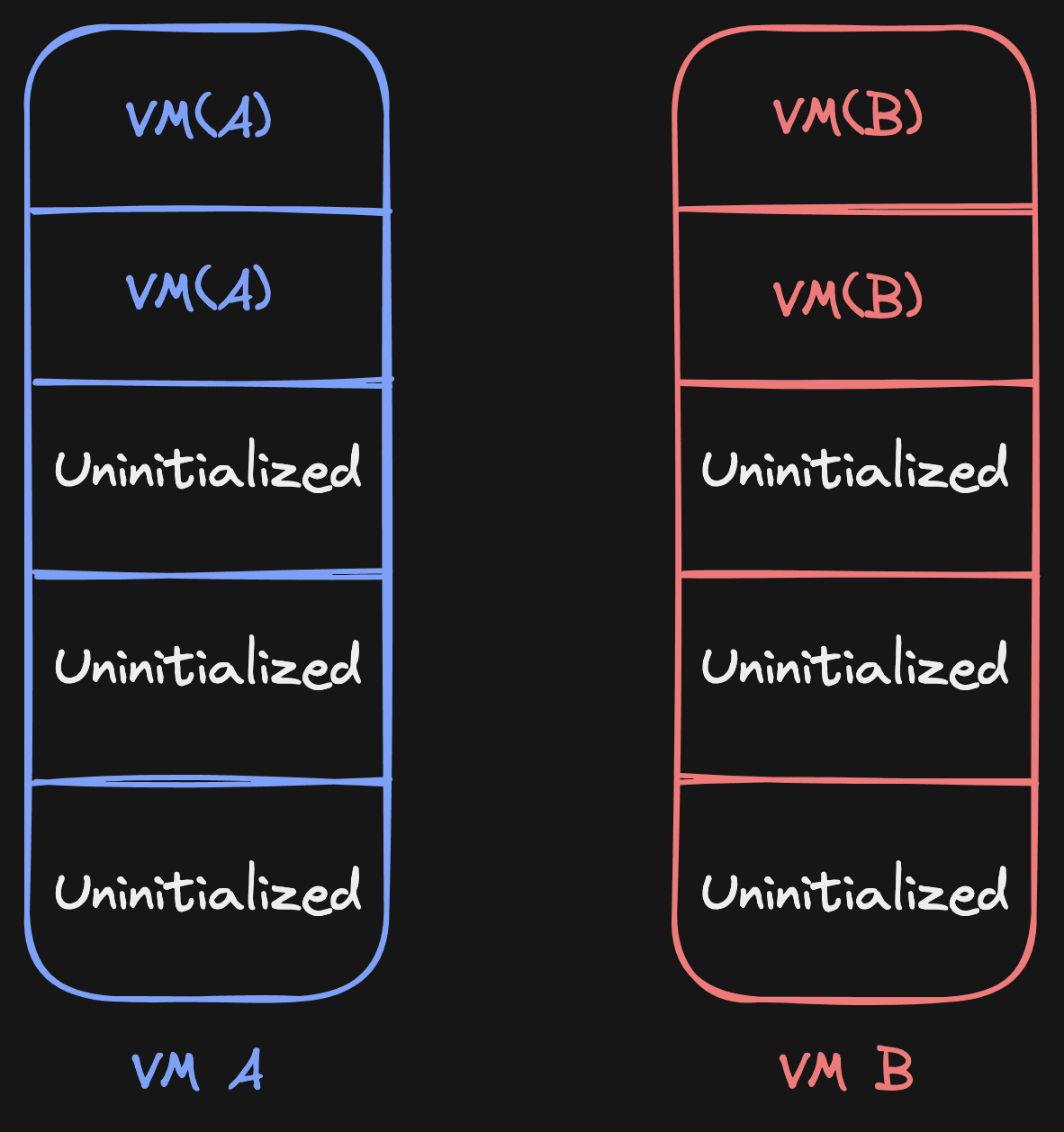
Let's play through it, as an exercise. Let's say VM B reads from page 1. According to the page source table, it needs to read from its source (VM A). It does this by copying the page, and then it sets the source of page 1 to VM B (itself):
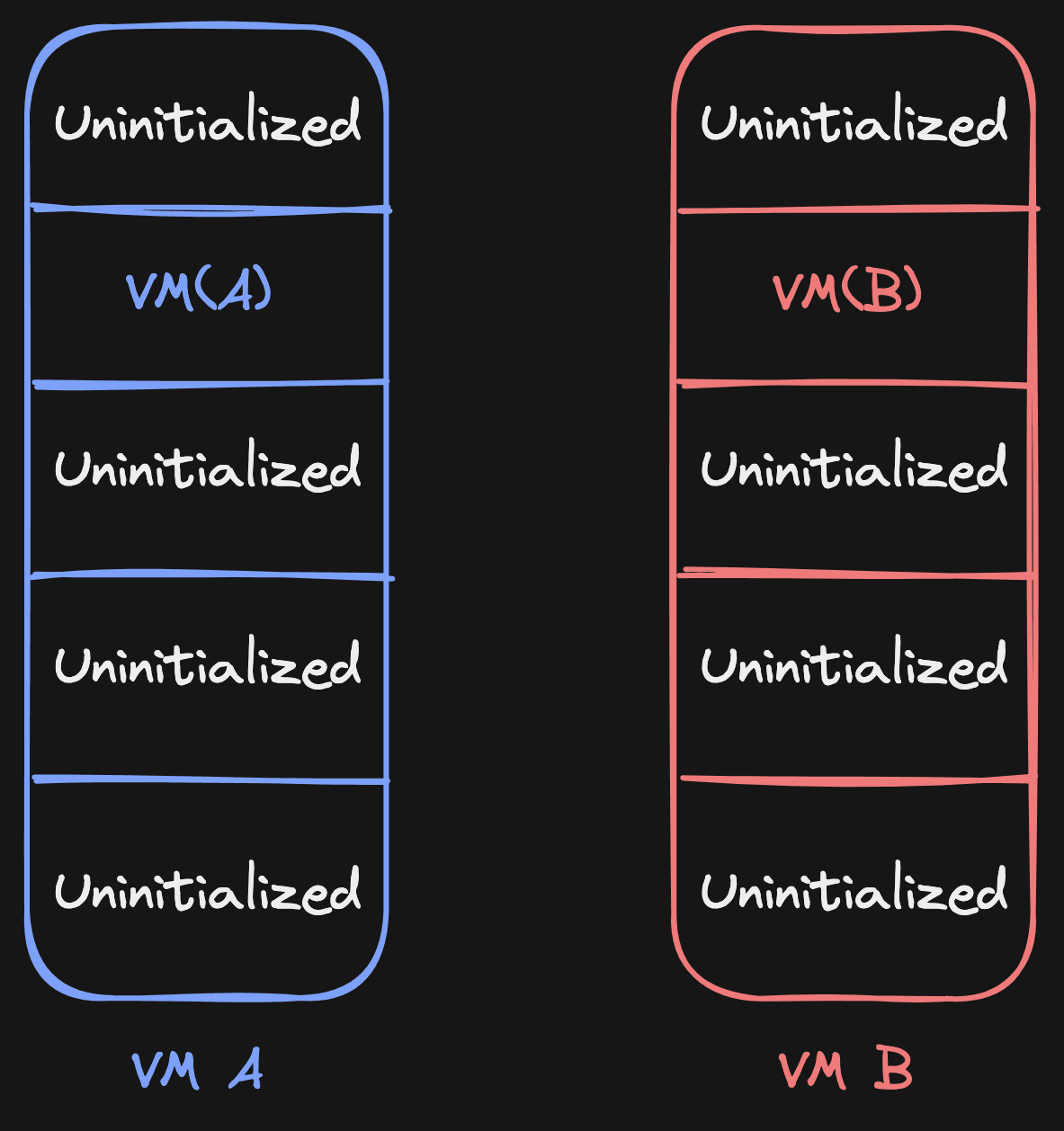
When VM C is created now, it could both have VM A sources and VM B sources in its list, and it knows exactly for every page where to get it from. No need to traverse up or down. For example, this is a valid case:
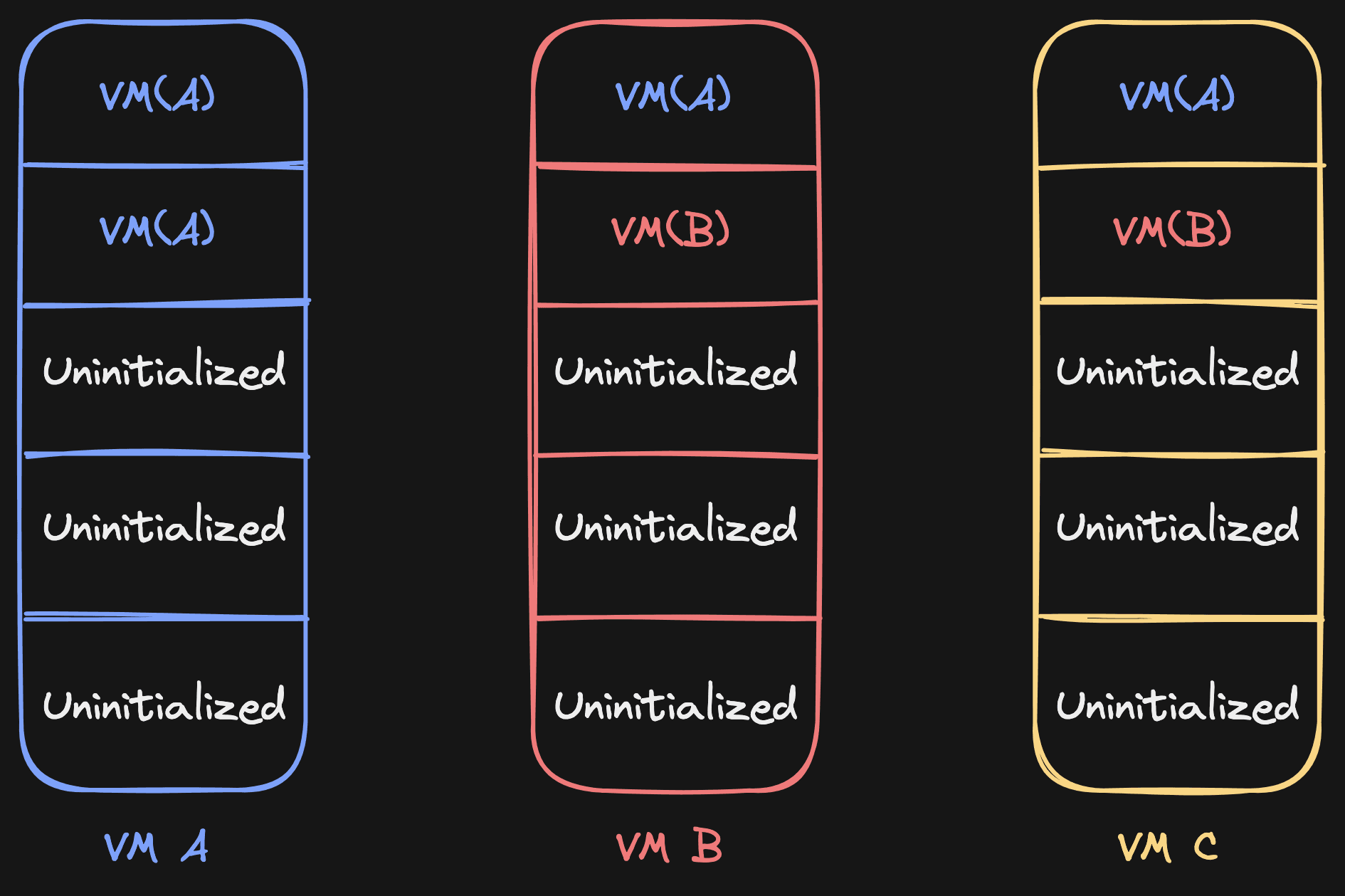
Writes also become easier to handle. Let's say we're in this situation:
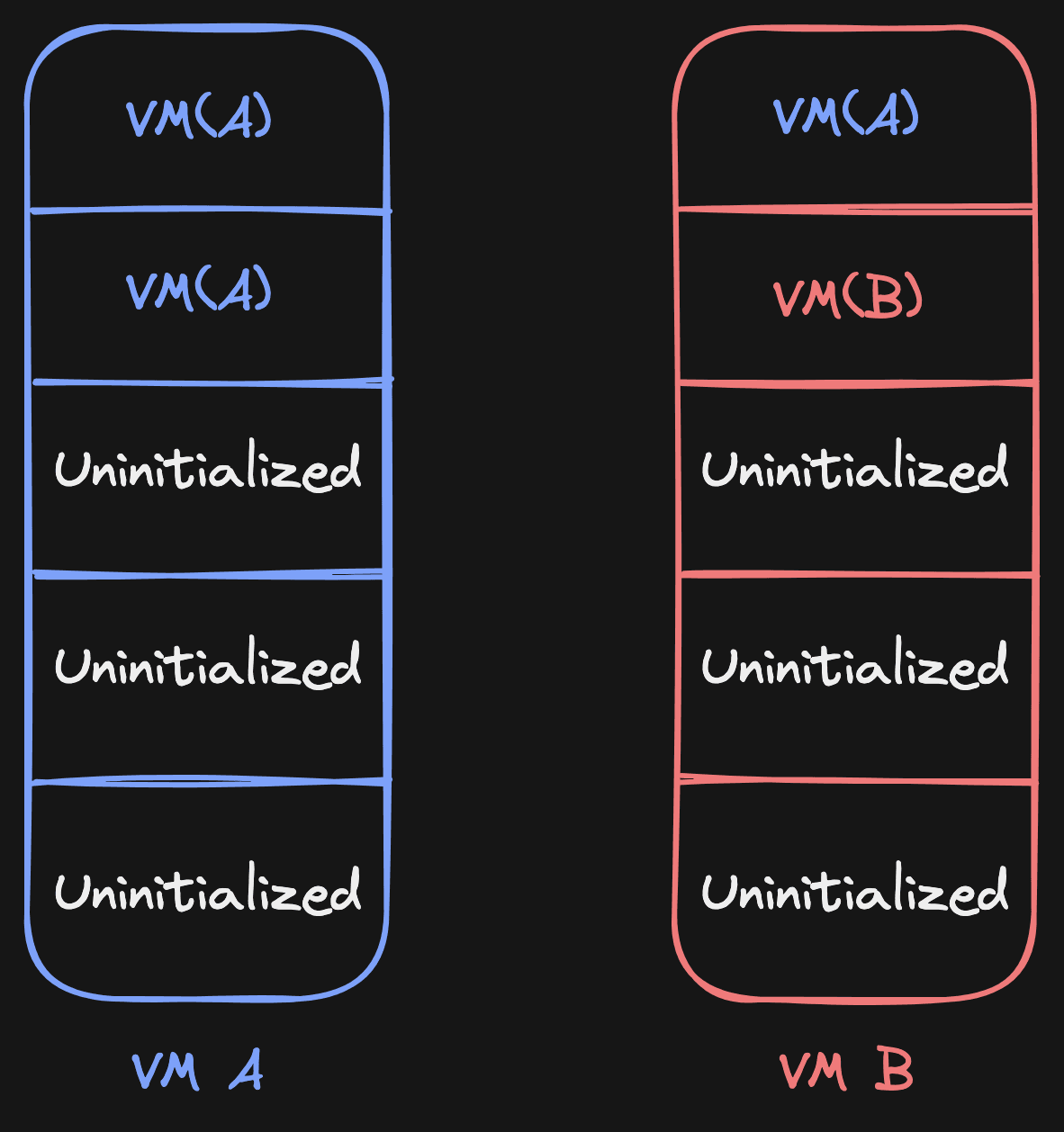
When we try to write to page 1 in VM A and a write-protect event comes in, we will check all the
VMs that have VM("A") as source for page 1, and we'll eagerly copy to those
VMs. Once that has been done, we'll point page 1 for these VMs to themselves:
This page source table concept does not only make it simpler to manage, well, page sources. It also opens the possibility to add new sources. Here are the sources we have today:
enum PageSource {
Uninitialized, // Not initialized (zeroed memory)
Vm(String), // Memory from another VM
File(Path), // Memory from a file
ZstdCompressedFile(Path) // Memory from a zstd compressed chunk in a file
}And we can add additional ones in the future (PageSource::Network?).
I'm writing another post about how we load compressed memory directly into the VM, and how we make to decompress fast enough to keep VMs fast.
Here's an example of how efficient it can be:
- VM A can start from a memory file and start with all its sources on
PageSource::File. - VM B can be cloned from it, and then it knows to read from the same file for its memory.
This is the last piece of the puzzle that enables cheap forking of memory. After enabling this new UFFD handler, our live (CoW) forks became instant, and the dev server of clones became available within 2 seconds (again). Our P99 also significantly decreased:
| Avg Fork Speed (ms) | P01 Fork Speed (ms) | P99 Fork Speed (ms) | |
|---|---|---|---|
| Filesystem Fork (Old) | 1954 | 701 | 17519 |
| UFFD Fork (New) | 921 | 336 | 1833 |
Conclusion
At CodeSandbox we can now clone the memory of VMs in a Copy-on-Write fashion without having to go through the filesystem, which significantly speeds up our VM clone speeds.
It also opens up the opportunity to load memory from new sources, like (compressed) files, or
even the network. A couple of months after enabling UFFD forks, we also enabled loading memory from compressed files
directly using zstd. Keep an eye for a new post about this!
We can now reliably fork a VM within 1.5s, regardless of how much memory is used for the VM:
Suffice to say, we're fired up about this solution—and there's still a ton of tweaks and improvements we can do to make VM resuming/cloning better. As we learn more, I'll write follow-up posts, either on this topic or about something else that relates to how we host Firecracker microVMs.
The possibilities of VM cloning are endless! For example, for repositories running on CodeSandbox, every branch will have its own VM. If you start a new branch, we'll clone the VM of the main branch, and connect you to that VM. This way you can work on multiple branches at the same time without having to do git checkout, or git stash or things like database migrations.
As I mentioned at the beginning of the post, you can experience this in action by forking this Next.js example or importing your GitHub repo! If you have more questions about this workflow, don't hesitate to send me a message on Twitter.
Finally, a big thank you to Peter Xu in particular. He found the last bug that we were facing for getting this to work, and without his help we would never have been able to get this implementation off the ground. It was an emotional rollercoaster, but in the end it got successfully deployed!