The History of State Management at CodeSandbox
A long, winding road from our Redux origins to our latest explorations using React and Impact.


At CodeSandbox, we run your code in our cloud infrastructure, configure the environment for you and keep your code always ready, behind a shareable URL. Give it a try with this Next.js example or import your GitHub repo!
CodeSandbox, the application
CodeSandbox provides a cloud development environment with a powerful microVM infrastructure, supported by several services and an API. This enables developers all around the world to collaborate and build products together. At the very front, we have the web application, where it all comes together and ignites the CodeSandbox experience.
CodeSandbox is not your typical web application. There is surprisingly little traditional data fetching—we only do server-side rendering for SEO purposes and there is only a single page, the editor. This reduces a lot of complexity in developing a web application, but looking at the editor you would quickly label it as a complex piece of software. In reality, this complexity comes from the amount of state and management of that state to create the experience of CodeSandbox.
We are about to embark on our fifth iteration of state management. Since its birth 7 years ago the web ecosystem has had big and small influences. In parallel with building our experiences, we also continuously discuss and reflect on these ecosystem influences and evaluate how they can benefit us. The ultimate goal for us is to use tools that allow us to continue adding new experiences with as little friction as possible.
So as we start this fifth iteration of state management, we have a golden opportunity to reflect on our previous iterations.
It all started with…
At the inception of the CodeSandbox application, Redux was the big hype. Redux enabled an important capability in terms of state management: it exposes state to any component in the component tree without the performance issues of using a React context. It does this by allowing you to select what state should cause reconciliation of the consuming component. In other words, Redux gave CodeSandbox a global state store where the current user, the current sandbox, the live session state, the layout state, etc. could live and be accessed by any component.
With a high degree of state used across components in deeply nested component trees, Redux solved the most critical aspect of managing the state of CodeSandbox. That said, as CodeSandbox grew it had two problems: understanding how the application works and it had subpar performance.
As an example, when you loaded a sandbox the application would need to run an asynchronous flow that included 21 state updates and 9 effects. With Redux this flow was expressed across 10 different action, reducer, and component files. So as a developer, asking yourself the question “What happens when we load a sandbox?”, it was incredibly difficult to infer.
The performance issues we faced with Redux are really the same performance issues you have with React in general. Even though Redux allowed us to narrow down what state components require, it is impossible for a human being to infer how the scope of the state will affect the component reconciliation performance as a whole.
Getting insight
This led us to our second iteration: Cerebral JS. Cerebral would solve both of these problems. By using a sequence API for our complex asynchronous flows of state updates and effects, which also includes a visual development tool for those sequences, we had more insight and understanding of how the application works. Even though new developers would need to learn an API, that learning curve was much smaller. Also, it ensured everyone had the exact same mental model and a good understanding of what happens “when a Sandbox loads”.
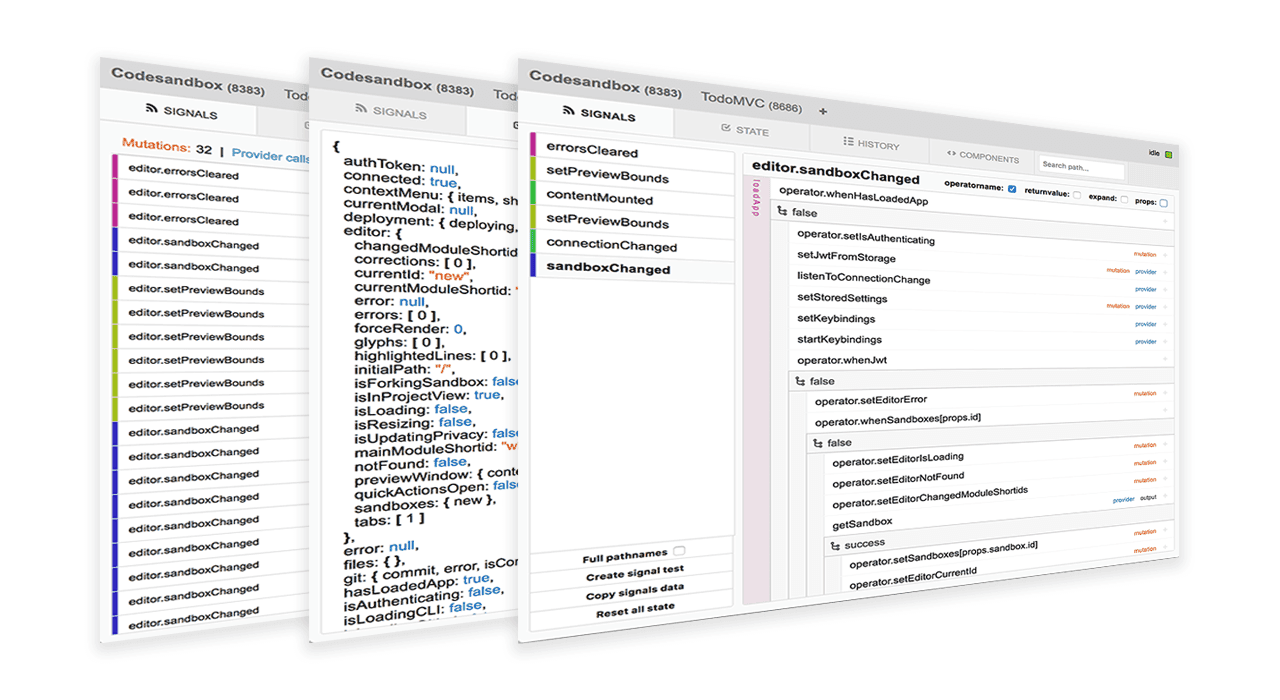
The Cerebral JS devtools give deep insight into the state management of the application.
The performance gains came from us combining Cerebral with Mobx. Now our components would automatically observe any state they accessed as opposed to us manually trying to optimize state access with selectors.
In the following presentation you can learn more about the journey of Cerebral JS and how my own journey crossed paths with CodeSandbox.
A presentation at React Finland about Cerebral JS and using it for CodeSandbox.
I hate TypeScript, I love TypeScript
As time passed, TypeScript came on the scene. Its promise of painless refactors and reduced risk of regressions was something we desperately needed. As CodeSandbox grew we were reluctant to change existing code. We were always on high alert after deploying changes and “We did not test it it well enough!” became a point of cultural friction for us.
Cerebral JS, with its exotic declarative sequence API, would never work with TypeScript. That fact, combined with the introduction of Proxies to the language, gave the perfect excuse to throw another state management library into the ecosystem. Overmind was born and it was built from the ground up to be a spiritual successor to Cerebral. It took the same conceptual approach, but with an API that was type friendly and still with just as much insight using its development tools.
A presentation at a meetup in Oslo about how to think about application development separate from user interfaces.
At this point, it would seem that all our challenges were solved. We had great insight into our application, we did not worry about performance, adding new features was straightforward, and with TypeScript we gained more confidence to refactor and deploy our code. But one day we wanted to make TypeScript even stricter, so we turned on strictNullChecks.
Being yelled at by TypeScript
Strict null checking is a feature of TypeScript that gives an error if you try to access a value that might be null or undefined. Without this feature, the following does not give an error:
type State = {
// The project state might not be initialized
project?: {
title: string
}
}
const state: State = {}
state.project.title // This does not give any errorAs we turned on the feature, TypeScript got very upset with us, to say the least. We had so many errors that we decided not to do it. But it was not the number of errors that demotivated us, it was the realization of an underlying message from TypeScript: “You developers have a lot more context about the code than I do”.
This sounds a bit abstract and cryptic, but it is an important point. When you work with global state stores you are in a global context that is initialized before the rest of the application. That means any state that is lazily initialized through data fetching or other mechanisms has to be defined as “possibly there”. This makes sense from the perspective of the global state store, but from the perspective of the consumers of that global state store, there is no guarantee that the state you access has been initialized or not. In practice, that means whenever you consume lazily-initialized state from a global state store you have to verify:
type State = {
project?: {
title: string
}
}
const state: State = {}
if (state.project) {
state.project.title
}When you are writing code in a context where you know that the project must have been initialized, for example in a nested component or an action, you have to write additional code to explain TypeScript that this is indeed a valid context to access the project. And in a complex application like CodeSandbox, this happens everywhere. You want TypeScript to have a deep understanding of your codebase and help you, but in this situation, you have more understanding of the codebase and need to help TypeScript. Something is not right in the world.
Putting context into state
Around this time, CodeSandbox had become a company and we were planning, unknowingly at the time, our move into the Cloud Development Environment space. In the web ecosystem, state machines were the big thing and we also experimented with this:
Using a state machine would help us make our code more aware of the context it runs in, and also be more explicit about what contexts it can run in. This experimentation held a lot of promise, at least in theory, and we decided to build our new editor using React primitives with some patterns and minor abstractions to embrace this concept.
Even though this fourth state management iteration did improve the challenge we just discussed, it came short on some of the already solved challenges with our previous iterations. Specifically, we had challenges with performance again as we were relying on React contexts to share state. Also, we were used to imperative actions, which were now replaced with reducers and state transition effects. This split our logic into different files and created indirection.
In practice, it became very difficult to reason about “What happens when this action is dispatched?”. Just the fact that you could not CMD + click an action dispatch in the code and go to its implementation, reading line by line what it does, became a big friction for us.
Exploring React contexts for state management was still an important experience. Instead of thinking state trees, we were now thinking and practicing hooks composition for our state management. And with the advent of suspense, error boundaries and new data fetching patterns in React, it all culminated in our fifth iteration.
Putting state into contexts
With our fifth approach, we embrace the fact that React has contexts to share state management across components, allowing us to initialize state closer to where it is used and take advantage of React data fetching patterns. The only real problem with contexts is their performance. Even with projects like Forget, contexts will remain a bottleneck given that any state change within a context will cause reconciliation to all consumers of that context.
Without going into all the bells and whistles of this iteration, you can imagine a hook that does some state management:
export const useSomeStateManagement = () => {
const [count, setCount] = useState(0)
useEffect(() => console.log("Increased count to", count), [count])
return {
count,
increaseCount() {
setCount(count++)
}
}
}If you wanted that state management to be shared by multiple components, you would expose the hook in a context. But for that to run optimally you would have to:
export const useSomeStateManagement = () => {
const [count, setCount] = useState(0)
useEffect(() => console.log("Increased count to", count), [count])
const increaseCount = useCallback(() => {
setCount(current => current + 1)
}, [])
return useMemo({
count,
increaseCount
}, [])
}And even then any consumer of this context would reconcile whenever any state within the context changes, regardless of what state it actually accesses from the context.
With Impact we create a reactive context instead, using reactive primitives:
export const useSomeStateManagement = context(() => {
const count = signal(0)
effect(() => console.log("Increased count to", count.value))
return {
get count() {
return count.value
},
increaseCount() {
count.value++
}
}
})It does not matter how much state you put into this context—any consuming component reconciles based on what signals they access, regardless of context. You also avoid memoization, dependency arrays and the reconciliation loop altogether. But most importantly, you can use React data fetching patterns and mount these contexts with an initialized state.
An example from our exploration is how we mount a BranchContext within a SessionContext:
// We pass props coming from routing to mount our BranchContext
export function BranchContext({ owner, repo, branch, workspaceId }) {
// This component lives within our SessionContext, where we can
// fetch new branches and initialize Pitcher (Our VM process)
const { branches, pitcher } = useSessionContext();
// As we need the branch data first we use suspense and the new "use" hook
// to ensure that it is available before the component continues rendering.
// A parent Suspense boundary takes care of the loading UI
const branchData = use(branches.fetch({ owner, repo, branch, workspaceId }));
// Since Pitcher has progress events while resolving its promise, we consume
// the observable promise, which is just a promise in a signal, to evaluate
// its status
const { clientPromise, progress } = pitcher.initialize(branchData.id);
if (clientPromise.status === "rejected") {
throw clientPromise.reason;
}
if (clientPromise.status === "pending") {
return (
<h4>
{progress.message} ({progress.progress})
</h4>
);
}
// We mount the nested context for the branch, giving it the already fetched
// data and connected Pitcher instance. Any consuming component/context will
// safely be able to access the initialized data and Pitcher API without any
// additional type checks
return (
<useBranchContext.Provider
branchData={branchData}
pitcher={clientPromise.value}
>
<Branch />
</useBranchContext.Provider>
);
}Signals and observability is not a new thing, but it has a bit of a renaissance these days. For example, Solid JS, which is a great contribution to the ecosystem, binds its signals to the elements created, being “surgical” about its updates. With Impact and React, the observability is tied to the component. The drawback of that is that you are not as “surgically” updating the actual element bound to a signal, but you keep your control flow in the language. What that means is that there are no special components for lists, switch and if statements. No risk of challenges with typing or language features like destructuring creating unexpected behavior. You can keep your mental model of “It’s just JavaScript”, which I personally favor. And as components only reconcile based on signals accessed, it is a huge performance boost regardless.
We have been running an Engineer @ work stream where Danilo, Alex and I have been exploring these concepts and building prototypes to see how state management through reactive contexts would work for us. The Impact project is also available on GitHub if you want to follow its progress.
There are many kinds of applications you can build and they all have a mix of common and unique challenges. This article and the Impact project are about a very specific challenge for the complexity of state management required in the CodeSandbox editor. We are not aiming for a silver bullet, but something that works for our use case.
Maybe you have similar challenges and if not, I hope this article leaves you with some thoughts for reflection. Thanks for reading!

